《Dispersive Loss:重新审视表征学习中的对比损失》
1. 研究背景与动机
对比学习是一种常见的自监督表征学习方法,其核心思路是将“相似样本对”(正样本对)拉近,将“不同样本对”(负样本对)推远arxiv.org。典型做法如InfoNCE损失,会对来自同一图像的两种增强视图施加相似度上界,对不同图像样本施加差异度下界arxiv.org。InfoNCE等对比损失在图像识别预训练等任务中取得了显著效果arxiv.org。然而,它也存在一些局限:首先,需要为每个样本构造正样本对(通常通过数据增强获取)并维护大量负样本,这增加了训练复杂度且对内存消耗较高arxiv.org。其次,当将这种方法直接用于生成模型(如扩散模型)时,正样本对难以定义;扩散模型训练本身以去噪回归为目标,如果再添加额外的视图变换容易干扰原始训练流程arxiv.org。事实上,扩散生成模型通常只依赖于回归损失,缺乏对表示的显式正则化arxiv.org,这与图像识别领域对表示学习的重视形成对比arxiv.org。
针对上述问题,研究者提出了Dispersive Loss(分散损失)。该方法的动机在于:一方面,希望在无需额外正样本或预训练模型的条件下,引入一种自监督正则化来丰富模型内部的表征;另一方面,希望保持扩散模型训练流程的“轻量”和“自给自足”。因此,Dispersive Loss被设计成对内部特征进行“离散化/扩散”的正则项,相当于传统对比损失中仅保留“推开不同样本”的作用,而舍弃“拉近同样本”的部分arxiv.orgarxiv.org。
2. 方法介绍
Dispersive Loss的核心思想是对生成模型的中间特征进行正则化,使它们在表征空间中尽可能“分散”。具体地,对于一个批次的输入样本及其对应的中间表示${zi}$,总的损失函数由原有的回归损失$L{\rm diff}$(如扩散模型的去噪MSE)与新增的分散损失$L_{\rm disp}$构成:
其中$\lambda$控制分散损失的权重arxiv.org。Dispersive Loss直接作用于模型的中间激活,无需增加任何投影头或可训练参数arxiv.org。这种设计保证了方法的自洽性:当$\lambda=0$时,模型退化为原始基线;在非零时,也不改变原有的训练流程,无需额外的数据增强或视图采样arxiv.org。可以说,Dispersive Loss是“对比损失但无正样本”的自监督目标:回归损失本身已经为每个样本提供了对齐的目标(正样本),因此我们只需要保留推开的作用即可arxiv.org。 以InfoNCE为例,原始InfoNCE损失可形式化为:
其中$zi$和$zi^+$是同一样本的两种视图表示,$d(\cdot,\cdot)$衡量相似度(如负余弦距离),$\tau$为温度系数arxiv.org。该损失同时包含拉近正样本(分子项)和推远负样本(分母项)的作用。构造Dispersive Loss时,研究者将正样本项舍去,仅保留推离的部分。具体而言,对所有样本表示求两两距离并施加对数平均,可得到InfoNCE形式的分散损失(文中Eq.6):
这个式子等价于对批次中任意两样本之间的距离取平均并对其负号求对数arxiv.org。从直观上看,该损失鼓励所有样本表示之间距离变大,实现了特征向量在空间中均匀分布(类似于“Uniformity”目标)arxiv.org。作者还介绍了其它变体:如仅保留负样本的Hinge损失或Covariance损失,也都能作为Dispersive Loss的实例arxiv.orgarxiv.org(表1总结了这些变体)。实验表明,基于InfoNCE的距离形式通常效果最佳arxiv.org。
与原始对比损失相比,Dispersive Loss有几个显著区别:
- 无需正样本或增强:它不需要为每张图像构造第二视图,从而避免了数据增强过程对生成模型的干扰arxiv.org。
- 轻量自给:不依赖外部预训练模型或额外参数。与REPA等表示对齐方法不同,Dispersive Loss完全基于模型自身内部表示arxiv.org。
- 目标明确:只聚焦于增加样本间的“排斥”力,使特征分散arxiv.orgarxiv.org,而将正例之间的对齐交由回归损失自动完成。
3. 实验设计与结果
作者在ImageNet-1K(256×256)数据集上对多种扩散生成模型进行了验证,包括不同规模的SiT(Score Distillation Transformer)和DiT模型arxiv.orgarxiv.org。基线模型仅使用标准的扩散回归损失,然后与加入Dispersive Loss后的模型进行对比。评估指标为FID-50k(在ImageNet上常用的图像质量指标)。
- 总体提升:实验结果表明,加入Dispersive Loss后所有模型均获得了质量提升。例如,在SiT-B/2模型(80轮训练)上,基线FID为36.49,加入Dispersive Loss后降至32.35(相对降低11.35%)arxiv.org。在更大的SiT-XL/2模型中,80轮训练结束时无引导下的FID从18.46降到15.95(降低13.6%);引入classifier-free引导后也有相似的提升(6.02→5.09,-15.4%)arxiv.org。这些提升在不同模型规模(S/B/L/XL)和训练epoch数下均一致存在arxiv.orgarxiv.org。
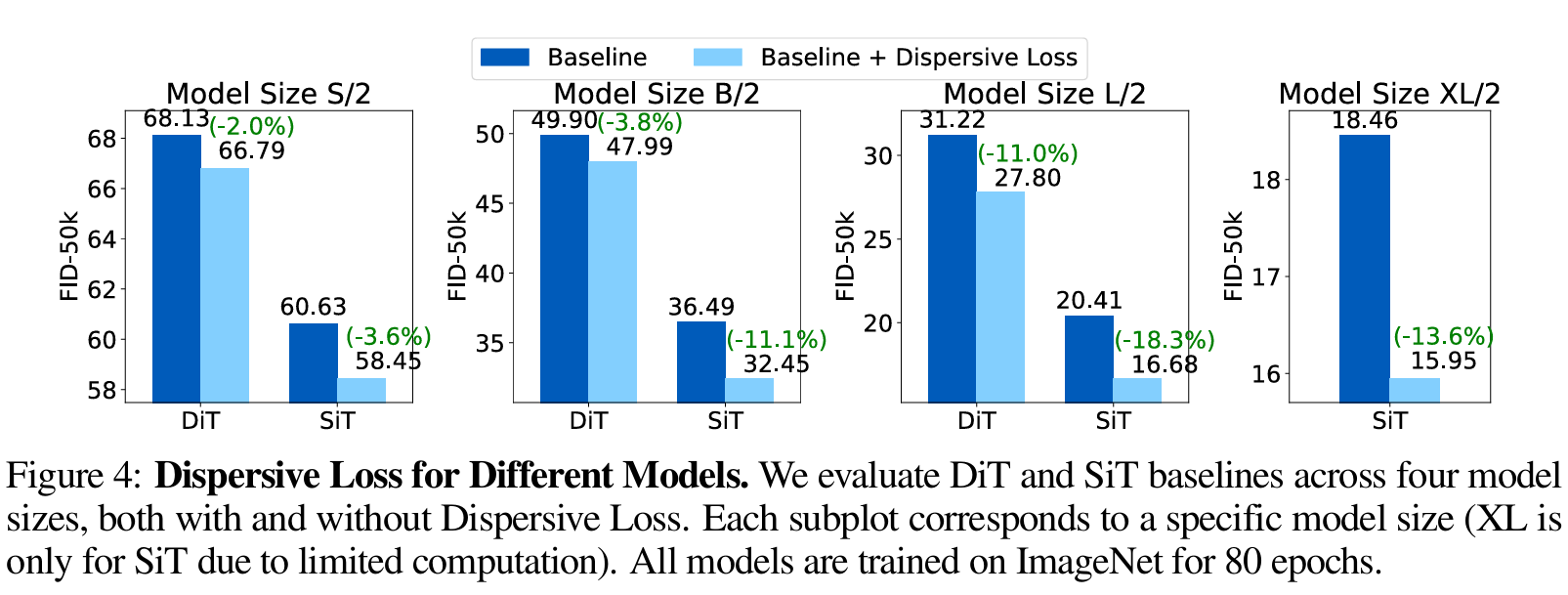
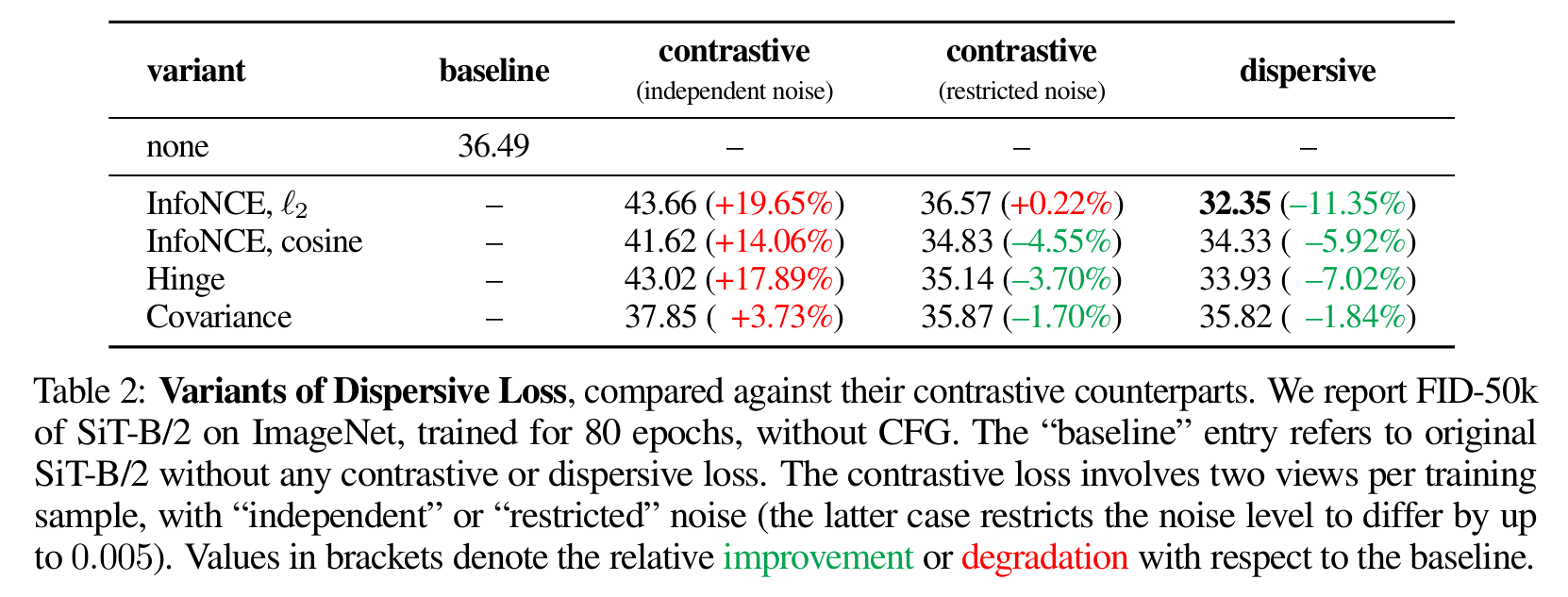
- 消融实验:作者对不同变体和超参数进行了分析。比较了InfoNCE(基于距离或余弦)、Hinge、Covariance等不同形式的Dispersive Loss(见表2);结果表明所有变体都优于不使用正则化的基线,其中InfoNCE距离形式效果最佳arxiv.org。此外,将Dispersive Loss应用于网络不同层次(Transformer的block)也均能降低FID(表3),在每一层均加入正则化可获得最大收益arxiv.org。研究还发现,正则化权重$\lambda$和温度$\tau$的选取对结果影响不大,在较宽区间内均明显优于基线arxiv.org。
- 与其他方法比较:Dispersive Loss还与REPA等方法做了对比。REPA依赖于外部预训练模型(如1.1B参数的DINOv2)来对齐表示,而Dispersive Loss完全自包含、无需额外数据。具体来说,在SiT-XL/2的实验证明,Dispersive Loss的FID为1.97,而REPA报告的对应数值为1.80arxiv.org。尽管后者略低一点,但考虑到Dispersive Loss不使用任何外部模型或数据,其性价比更高arxiv.orgarxiv.org。

- 单步生成测试:作者还将Dispersive Loss应用于最新的单步扩散框架MeanFlow。实验结果(见表7)显示,对MeanFlow-XL/2模型添加Dispersive Loss后,FID从3.43进一步降到3.21,刷新了单步生成的最好水平arxiv.org。这表明该方法不仅适用于多步模型,也可提高单步生成的质量。

总的来说,各项实验一致验证了Dispersive Loss的有效性:在不同数据集、不同模型规模和训练条件下,都显著改善了生成质量(FID降低10%余),而直接加入传统对比损失反而可能导致性能下降arxiv.orgarxiv.org。
4. 意义与影响
Dispersive Loss为表征学习和自监督学习领域带来了新的思路和贡献。首先,它提出了一种“无正样本”的对比学习框架,强调只利用负样本(或其等价形式)进行学习arxiv.orgarxiv.org。这一点在以往研究中较为少见:已有工作关注“无负样本”(如BYOL)的对比学习,而Dispersive Loss则开辟了“无正样本”对比学习的方向arxiv.org。从理论上看,这相当于把传统InfoNCE的对齐(alignment)部分交由其他目标承担,仅保留统一性(uniformity)的正则项,这为理解表示学习中的对齐-统一性的权衡提供了新视角。
其次,在应用层面,Dispersive Loss展示了自监督正则化能显著提升生成模型质量,而实现方式却异常简洁:无需任何额外数据、预训练或复杂架构,只需在训练过程中附加一个“散布特征”的损失项arxiv.orgarxiv.org。这种自洽而轻量的设计,使其易于集成到现有的生成模型训练流水线中。在大规模模型训练中这种正则化尤为重要:作者观察到更强的基础模型(如更大的Transformer)从Dispersive Loss中获益更多arxiv.org,表明它确实作为一种额外的正则项防止过拟合。在实践场景中,这意味着在训练像Stable Diffusion、DALLE等大型生成模型时,类似的分散正则化方法有望改善生成质量。
最后,这项工作从更宏观的角度促进了生成模型与表征学习的融合。作者希望通过Dispersive Loss“弥合生成建模与表征学习之间的差距”arxiv.org。具体来说,它把自监督学习中的思想带入了生成任务,为生成模型内部提供了一个显式学习多样化表示的机制。同时,该方法的普适性(适用于多种模型和任务)也启示我们:在其他不依赖预定义正样本对的任务中,比如自然语言生成、强化学习中的特征表示等场景,也可以考虑类似的正则化设计。
总结:Dispersive Loss提出了一种新颖且易用的表征学习损失,将对比学习中的“推异”机制提取出来单独应用,用于丰富模型的内部表示。该方法在图像生成任务上取得了显著提升,验证了其有效性;同时,它的简洁性和自包含性使其具有潜在的广泛适用性,为自监督学习和生成模型的研究开辟了新的方向arxiv.orgarxiv.org。