构建LLM代理:为什么“多代理”架构往往是坑?
核心思想与作者观点
作者指出,当前LLM(大型语言模型)代理框架的实际表现令人失望,尤其是那些推崇“多代理”协同工作的架构。他基于自身团队的试错经验,提出了一套构建可靠、长期运行代理的核心原则,并深入解释了为什么看似诱人的多代理架构在实践中往往会违背这些原则,从而导致系统脆弱且不可靠。
一、上下文工程原则:构建可靠代理的基石
作者认为,在LLM和AI代理的时代,我们正处于探索阶段,就像早期的网页开发者摸索HTML和CSS一样。而“上下文工程”是构建高效、可靠代理的核心,它比传统的“提示工程”更进一步,强调在动态系统中自动化地管理和提供模型所需的精确上下文。
构建代理的两大核心原则:
共享上下文(Share Context):
- 原则内容: 代理需要访问并理解完整的“对话历史”和“决策轨迹”,而不仅仅是孤立的消息或当前的指令。这意味着需要共享完整的代理追踪(full agent traces),而不仅仅是单个消息。
- 重要性: LLM模型虽然智能,但如果没有充分的上下文,它们也无法有效工作。就像人类在执行任务时需要了解前因后果、来龙去脉一样,代理也需要这些信息来避免误解任务、作出不连贯的决策。
- 反例(多代理分工模式的脆弱性):
- 架构示意图:
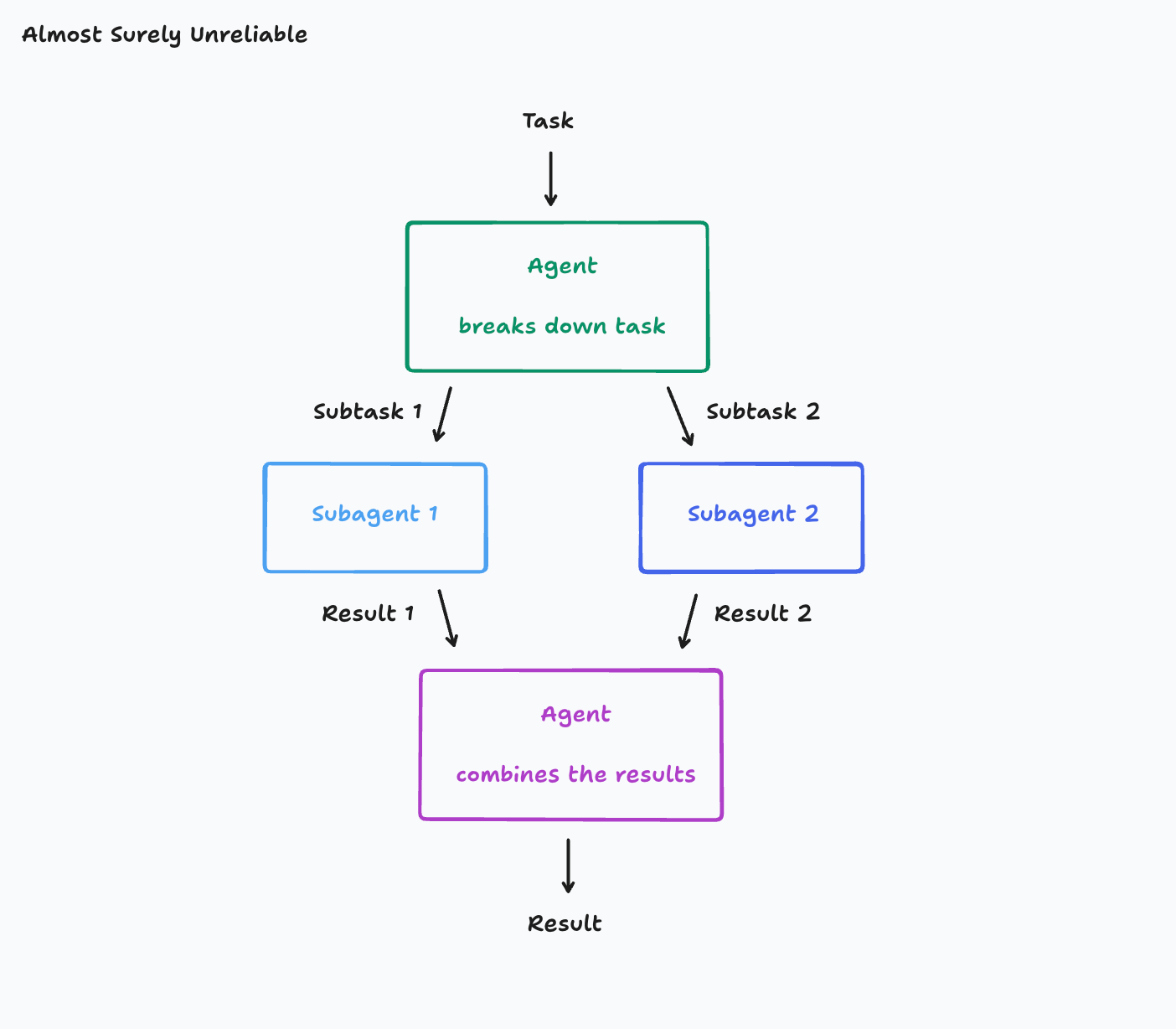
- 示例分析: 假设你的任务(Task)是“制作一个《Flappy Bird》克隆版”。这个任务被分解为子任务1“制作一个带有绿色管道和碰撞盒的移动游戏背景”和子任务2“制作一个可以上下移动的小鸟”。
- 问题所在: 如果子代理(Subagent)只接收到自己对应的子任务指令,而无法看到原始的完整任务描述以及主代理(Main Agent)在分解任务时所做的所有决策和考量,就很容易出现“误解”:
- 子代理1可能误解了“背景”的风格,开始构建一个看起来像《超级马里奥兄弟》的背景。
- 子代理2构建的小鸟可能完全不像游戏资产,或者其移动方式与《Flappy Bird》中的机制完全不同。
- 结果: 最终,主代理不得不面对将这两个“误解”的产物(不协调的背景和不符合要求的小鸟)结合起来的艰巨任务。
- 深层原因: 现实世界的任务往往有许多层级的细微差别。在多轮对话中,代理可能需要进行多次工具调用来决定如何分解任务,任何这些细节都可能对子任务的解释产生深远影响。如果子代理无法访问这些完整的历史信息,就容易产生偏差。
- 架构示意图:
行动包含隐含决策(Actions Carry Implicit Decisions):
- 原则内容: 代理的每一个行动都包含了其基于当前上下文所做出的隐含决策。如果这些决策是基于相互冲突的假设,那么最终的结果将是糟糕的。
- 重要性: 代理的行动不仅仅是执行指令,它们还反映了代理对任务的理解和其内部的“思考”过程。这些隐含决策必须保持一致性。
- 反例(多代理并行工作导致的不一致):
- 架构示意图:
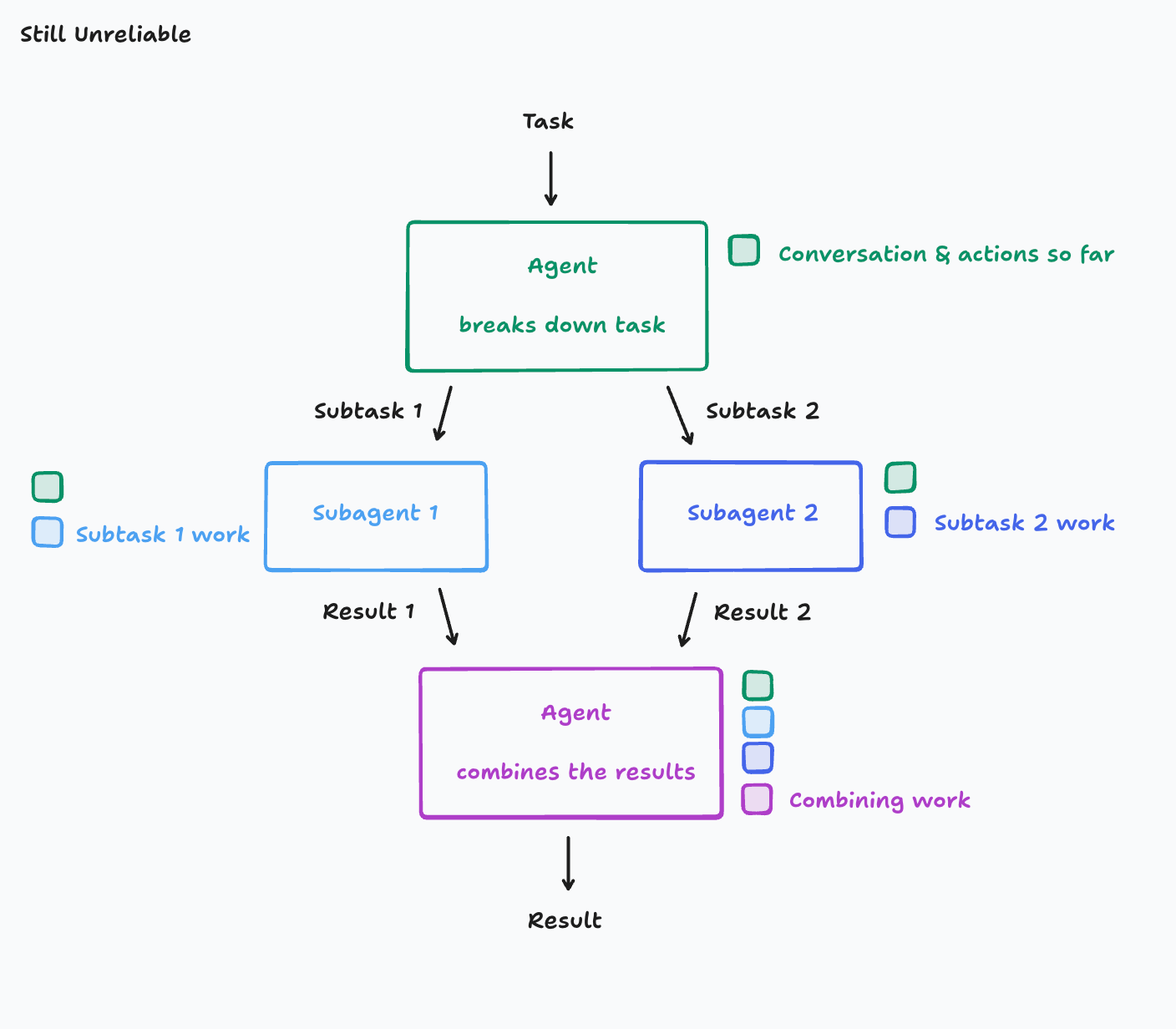
- 示例分析: 即使每个子代理都共享了完整的上下文(例如,它们都知道要制作《Flappy Bird》克隆版),但如果它们并行工作且彼此之间无法看到对方的实时进展,仍然会出问题。
- 子代理1在设计背景时,可能会选择一种特定的像素艺术风格。
- 子代理2在设计小鸟时,可能会选择一种完全不同的卡通风格。
- 结果: 最终你可能会得到一个鸟和背景视觉风格完全不同的《Flappy Bird》克隆版。
- 深层原因: 子代理1和子代理2所采取的行动是基于事先未明确规定或未实时共享的相互冲突的假设。它们无法看到对方正在做什么,因此它们的工作最终彼此不一致。
- 架构示意图:
二、构建长期运行代理的理论与最佳实践
作者强调,上述两条原则至关重要,几乎不值得违反。因此,在设计代理架构时,应默认排除任何不遵守这些原则的架构。
1. 最简单且可靠的架构:单线程线性代理
- 架构示意图:

- 优点: 在这种架构中,上下文是连续的。每个步骤都能完全访问之前所有的对话、决策和工具调用历史。这确保了代理的决策连贯性,并大大提高了可靠性。
- 局限性: 这种简单架构在处理非常大的任务时,可能会遇到上下文窗口溢出的问题。随着任务的进展,需要记忆和传递的信息量会急剧增加,最终达到LLM模型上下文窗口的限制。
- 上下文窗口溢出示意图:
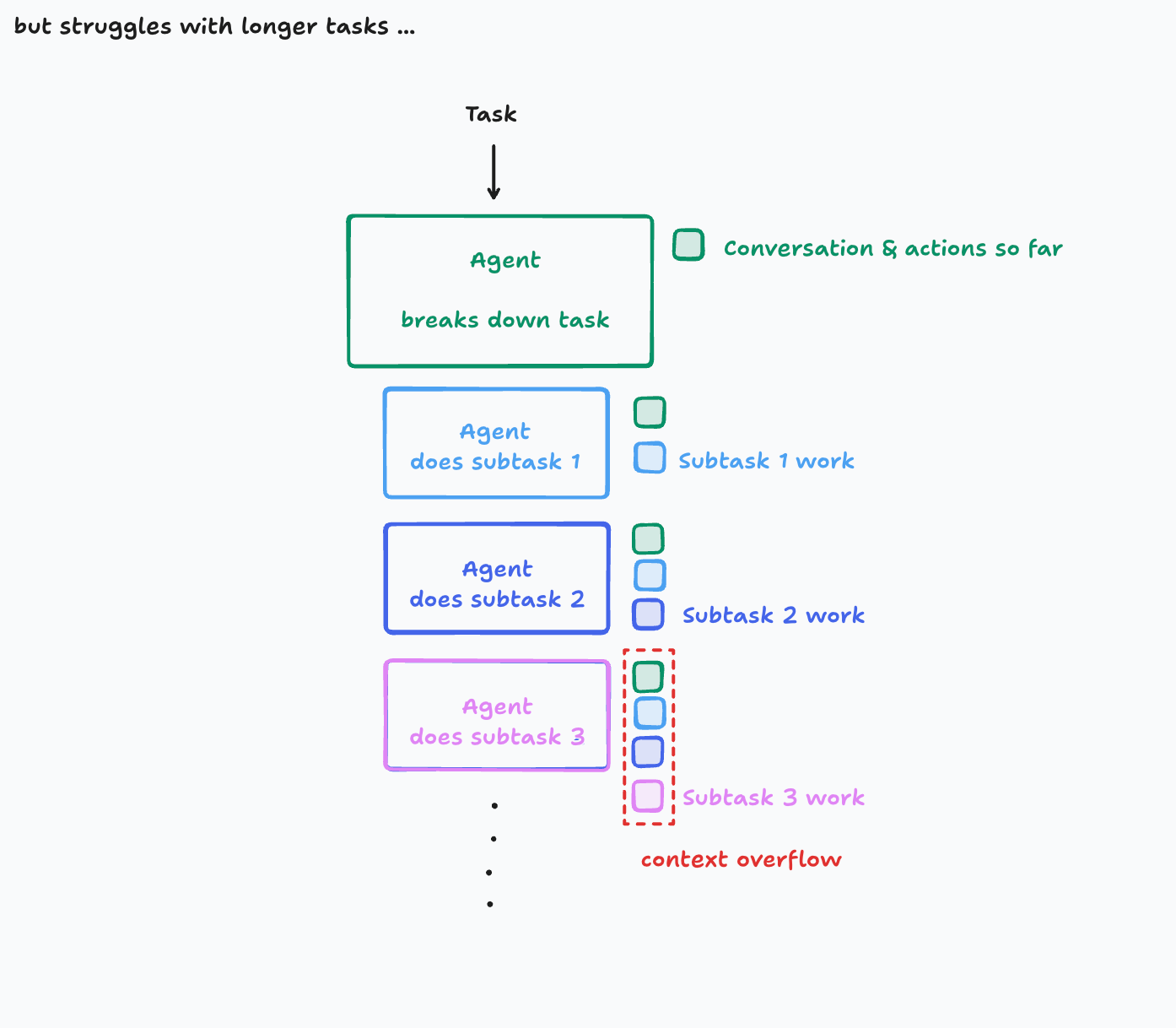
- 上下文窗口溢出示意图:
2. 优化方案:引入“上下文压缩”机制
- 架构示意图:
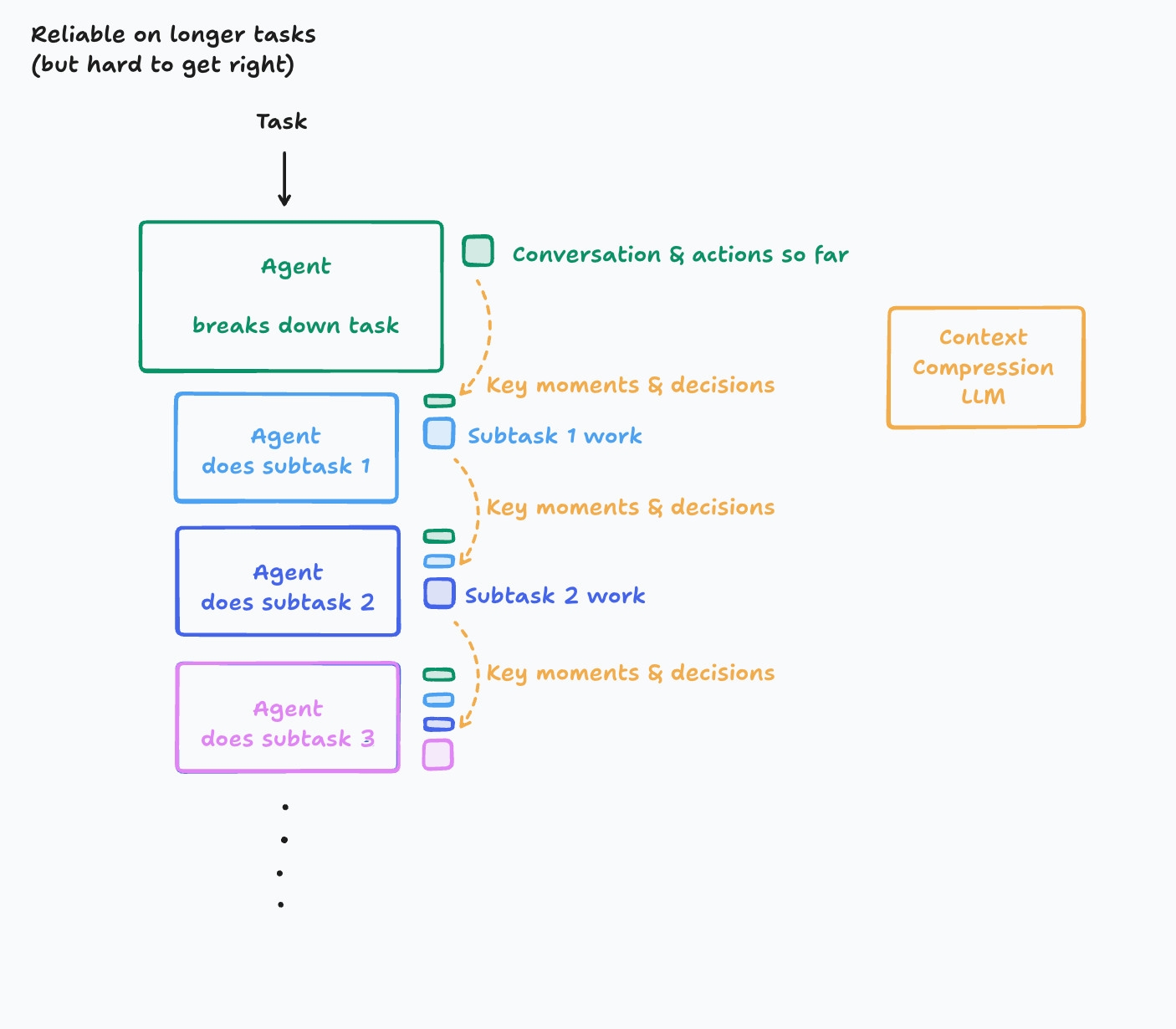
- 核心思想: 对于真正需要长时间运行且上下文非常庞大的任务,可以引入一个新的LLM模型,其主要目的是将历史的行动和对话压缩成关键细节、重要事件和核心决策。
- 实现挑战:
- 要正确地识别和提取“关键信息”是非常困难的。这需要投入大量精力去理解哪些信息是真正重要的,并设计一个能够高效完成这项任务的系统。
- 根据具体的应用领域,你甚至可能需要微调一个较小的模型来专门执行上下文压缩(Cognition团队已经这么做了)。
- 收益: 这种方法能够使代理在更长的上下文中保持有效性。
- 局限: 即使有了上下文压缩,仍然会最终达到一个极限。作者鼓励读者思考如何更好地管理任意长度的上下文,因为这是一个“相当深的兔子洞”。
三、将原则应用于实际:案例分析
作者建议,作为代理构建者,你必须确保代理的每一个行动都充分了解系统其他部分做出的所有相关决策的背景。理想情况是“每个行动都能看到一切”,但由于上下文窗口限制和实际权衡,这并不总是可能。你需要根据期望的可靠性水平来决定愿意承担的复杂性。
应用示例:
Claude Code 的子代理策略:
- 现状: 截至2025年6月,Anthropic的Claude Code 是一个生成子任务的代理示例。
- 关键设计: 它从不与子任务代理并行工作。而且,子任务代理通常只被分配回答一个具体问题,而不涉及编写任何代码。
- 原因分析: 子任务代理缺乏主代理的完整上下文,这使得它无法在回答明确定义的问题之外执行更复杂的任务(例如,编写代码)。如果让多个子代理并行运行,它们可能会给出相互冲突的响应,导致可靠性问题,正如前面《Flappy Bird》的例子所示。
- 收益: 在这种情况下,拥有一个子代理的好处是,子代理的所有调查工作(例如,查询信息)不需要保留在主代理的历史记录中,从而允许主代理的上下文追踪更长,避免过早耗尽上下文。
- 结论: Claude Code 的设计者采取了一种刻意简化的方法,以确保可靠性。
“编辑应用模型”的演变:
- 2024年普遍做法: 当时许多模型在编辑代码方面表现不佳。编码代理、IDE、应用构建器(包括Devin)普遍采用“编辑应用模型”。核心思想是,让一个大型模型输出代码修改的Markdown说明(例如,“将函数
foo改为bar”),然后将这些Markdown说明输入给一个小型模型来实际重写文件。这种做法被认为比让大型模型直接输出格式正确的diff更可靠。 - 问题所在: 这些系统仍然非常容易出错。小型模型常常会因为指令中最轻微的模糊性而误解大型模型的指令,从而做出不正确的编辑。例如,大型模型可能说“将函数
foo的所有调用都改为bar”,但小型模型可能只改了其中一处。 - 当前最佳实践: 如今,代码编辑的决策制定和实际应用更多地是由单个模型在一个动作中完成。这避免了信息在不同模型之间传递时可能产生的误解和歧义,从而提高了可靠性。
- 2024年普遍做法: 当时许多模型在编辑代码方面表现不佳。编码代理、IDE、应用构建器(包括Devin)普遍采用“编辑应用模型”。核心思想是,让一个大型模型输出代码修改的Markdown说明(例如,“将函数