整合一些算法和动图
冒泡排序
冒泡排序(Bubble Sort)是一种简单的排序算法,它重复地遍历要排序的列表,依次比较相邻的元素并交换它们的位置,如果它们的顺序错误。这个过程会不断重复,直到整个列表不再需要交换为止,最终得到一个有序的列表。
CodeBlock Loading...
选择排序
它的基本思想是每次从待排序的序列中选择最小(或最大)的元素,将其放在序列的起始位置,依次进行,直到所有元素都被排序完成。javajavajavajavajava
选择排序
CodeBlock Loading...
插入排序
将第一待排序序列第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列。
从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。(如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面。)
img
CodeBlock Loading...
快速排序
快速排序(QuickSort)是由东尼·霍尔(Tony Hoare)发展的一种高效排序算法。平均情况下,排序 n 个元素需要 Ο(nlogn) 次比较,而在最坏情况下,可能需要 Ο(n²) 次比较,但这种情况很少发生。事实上,快速排序通常比其他 Ο(nlogn) 算法更快,因为其内部循环可以在大多数硬件架构上高效实现。
快速排序通过分治法(Divide and Conquer)将一个序列(list)分为两个子序列(sub-lists)来进行排序。作为分治思想在排序算法中的经典应用,快速排序本质上是在冒泡排序基础上的递归分治法的扩展。
快速排序的最坏运行情况是 O(n²),比如说顺序数列的快排。但它的平摊期望时间是 O(nlogn),且 O(nlogn) 记号中隐含的常数因子很小,比复杂度稳定等于 O(nlogn) 的归并排序要小很多。所以,对绝大多数顺序性较弱的随机数列而言,快速排序总是优于归并排序。

在这里插入图片描述
CodeBlock Loading...
希尔排序
希尔排序(Shell Sort),又称递减增量排序算法,是插入排序的一种高效改进版本,但它不是稳定排序算法。
希尔排序的改进主要基于插入排序的两个关键特性:
- 插入排序对基本有序数据效率高:当数据几乎已经排好序时,插入排序的效率可以接近线性。
- 插入排序的局限性:插入排序每次只能移动一个元素,这使得它在处理大规模无序数据时效率较低。
希尔排序的基本思想是:
- 分组排序:首先将待排序的序列分割成若干个较小的子序列,并对这些子序列进行插入排序。子序列的分组是通过递减的增量(gap)来完成的。初始时,增量较大,随着排序的进行,增量逐渐减小。
- 最终排序:当增量减小到1时,整个序列的记录已经“基本有序”,此时对全体记录进行一次插入排序即可完成排序。
希尔排序的关键在于选择合理的增量序列。不同的增量序列对排序的效率有很大的影响,常见的增量序列包括初期的增量为 n/2,后续的增量逐渐减少到 1。
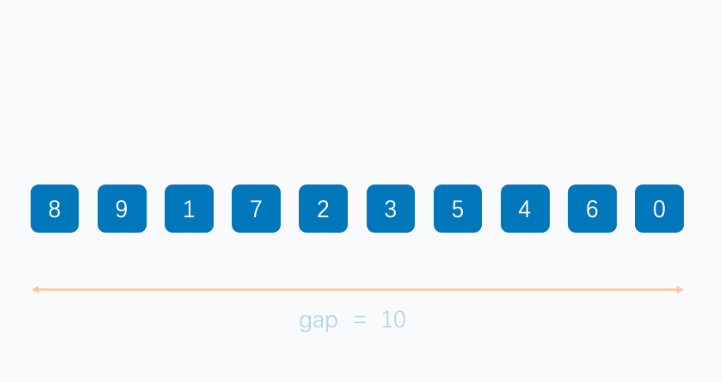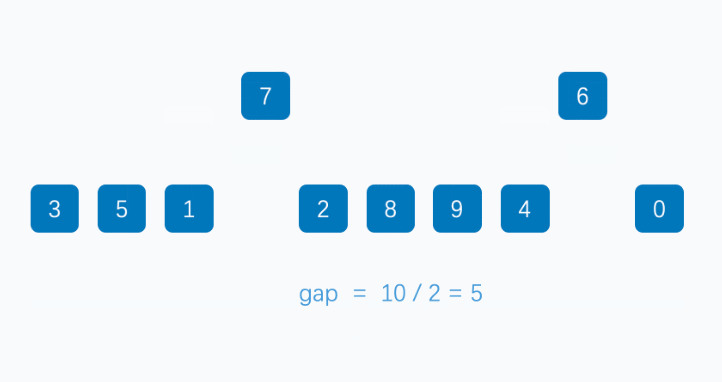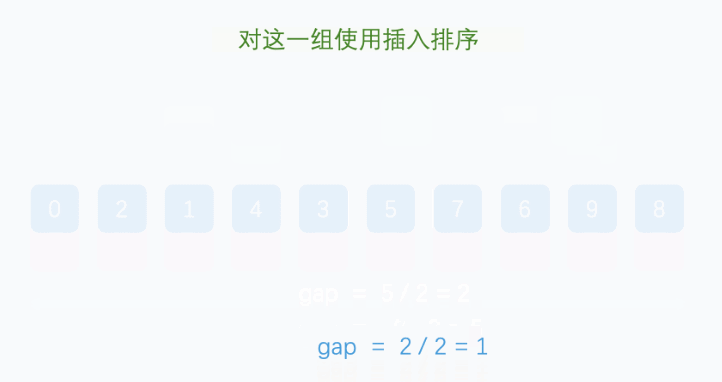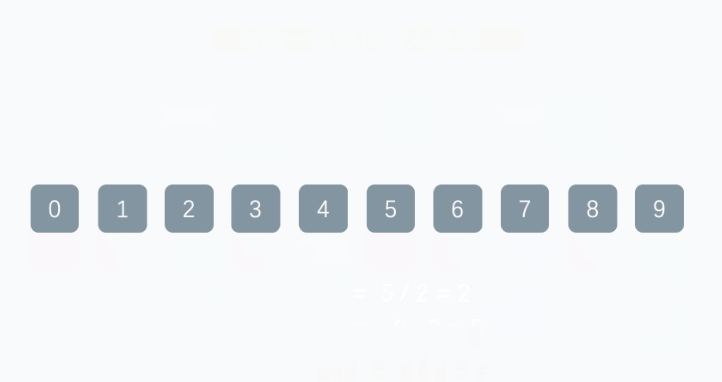
图片来源于网络
CodeBlock Loading...
归并排序
归并排序(Merge Sort)是一种基于分治法的有效排序算法。它的基本思想是将待排序的序列递归地分割成两个子序列,直到每个子序列仅包含一个元素,然后将这些子序列逐步合并成一个有序序列。归并排序可以分为自上而下的递归实现和自下而上的迭代实现两种方法。

请添加图片描述
CodeBlock Loading...
堆排序
堆排序(Heap Sort)是一种基于堆数据结构的有效排序算法。它利用堆的特性来实现排序,通常使用最大堆或最小堆来完成。堆排序的基本思想是将待排序的序列转换为一个堆,然后逐步从堆中提取最大或最小值,并调整堆的结构,从而实现排序。
堆排序的基本步骤:
- 构建堆:将待排序的数组构建成一个最大堆(或最小堆)。在最大堆中,每个父节点的值都不小于其子节点的值。在最小堆中,每个父节点的值都不大于其子节点的值。
排序:
- 从堆中提取根节点(最大值或最小值),将其与堆的最后一个元素交换。
- 重新调整堆,使其重新满足堆的性质。
- 重复以上步骤,直到堆为空。

img
CodeBlock Loading...
计数排序
计数排序是一种线性时间复杂度的排序算法,适用于整数范围有限的场景。它的基本思想是通过统计每个元素出现的次数来确定元素的位置,从而完成排序。以下是计数排序的基本步骤:
- 确定范围:首先确定待排序元素的最大值和最小值。这个范围将决定需要创建的计数数组的大小。
- 创建计数数组:根据元素的范围创建一个计数数组。数组的索引表示待排序元素的值,数组的值表示该值出现的次数。
- 统计元素出现次数:遍历原始数据,将每个元素对应的计数数组位置的值加一。
- 计算累积计数:对计数数组进行累积求和,以确定每个元素的最终位置。
- 生成排序结果:根据累积计数数组中的信息,将元素放入正确的位置,生成排序后的数组。
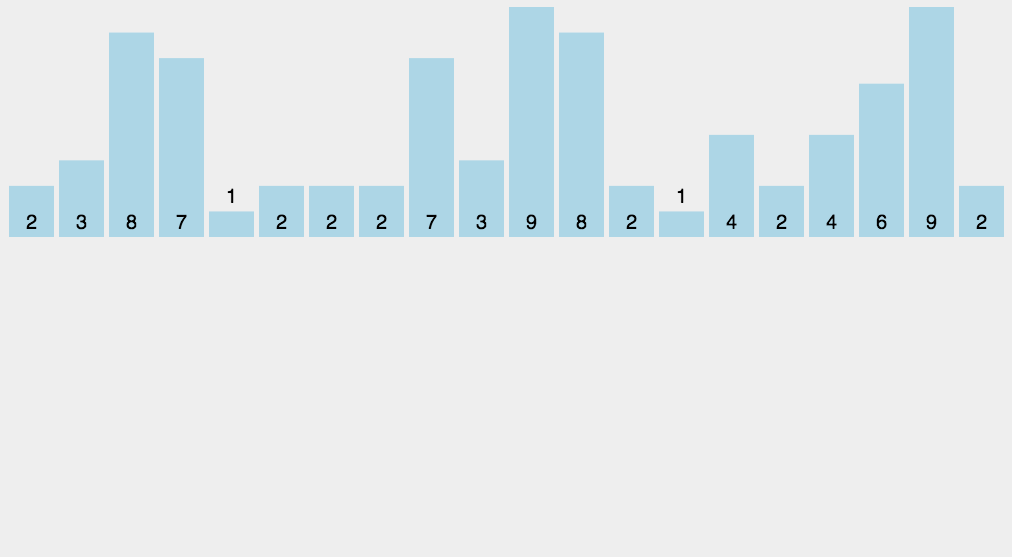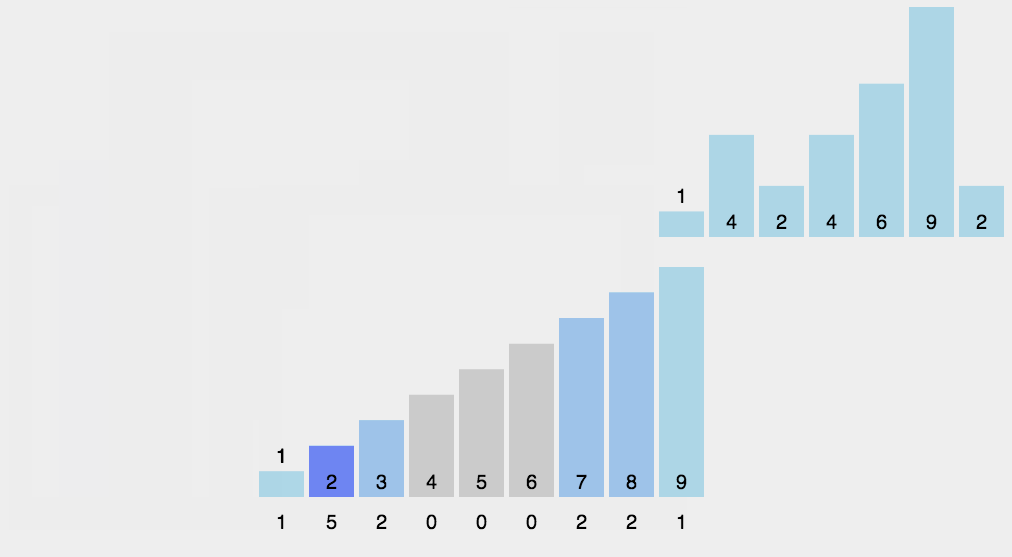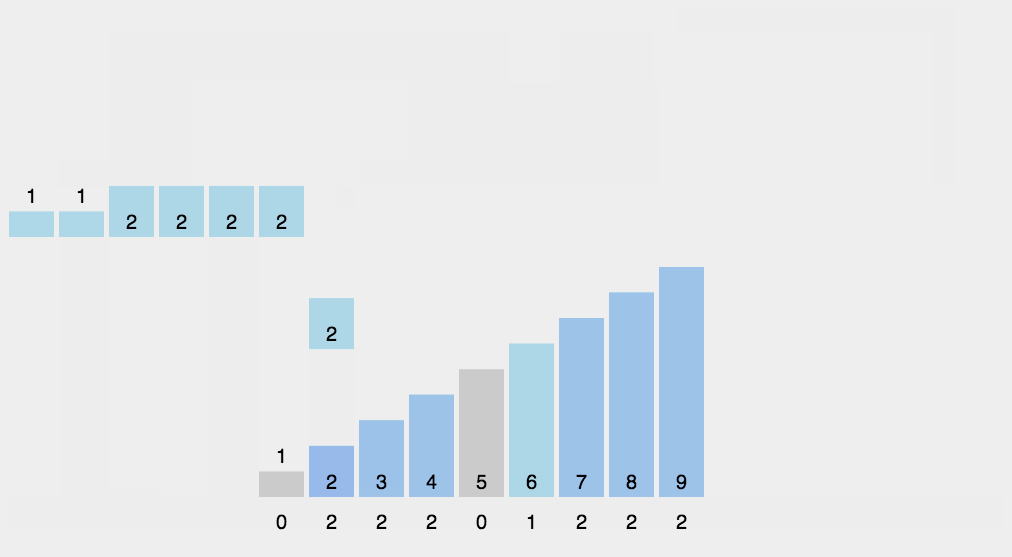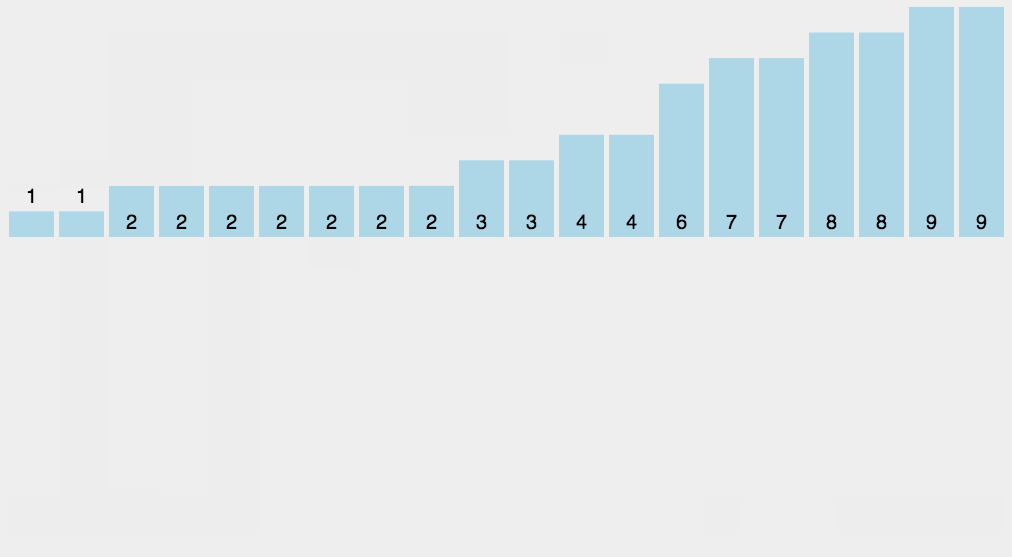
img
CodeBlock Loading...
桶排序
桶排序(Bucket Sort)是一种基于分布的排序算法,特别适用于输入数据分布均匀的情况。它将元素分到多个桶中,再对每个桶内的元素进行单独排序,最后将所有桶内的元素按顺序合并,从而完成排序。
桶排序的基本步骤
- 创建桶:根据输入数据的范围和分布情况,创建一定数量的桶。每个桶代表一个区间。
- 分配元素到桶:遍历输入数组,将每个元素根据其值放入相应的桶中。
- 对每个桶内的元素进行排序:选择合适的排序算法(如插入排序或快速排序)对每个桶内的元素进行排序。
- 合并所有桶的排序结果:将每个桶中的元素按顺序拼接起来,形成最终的有序数组。
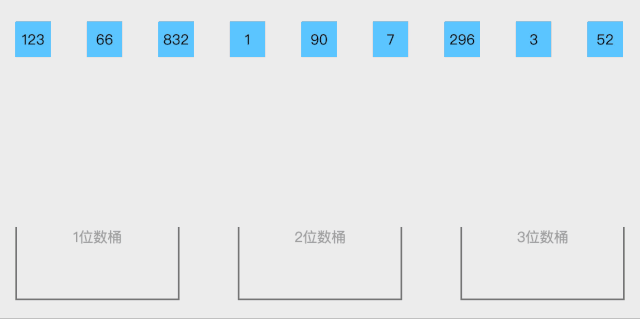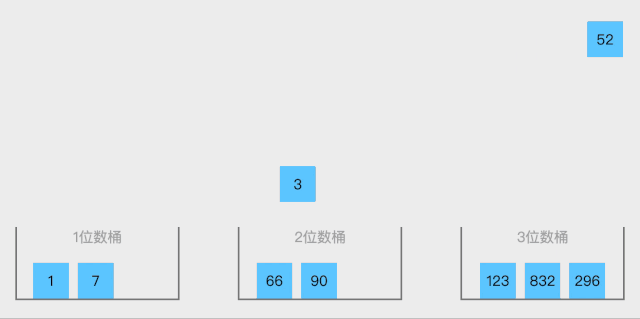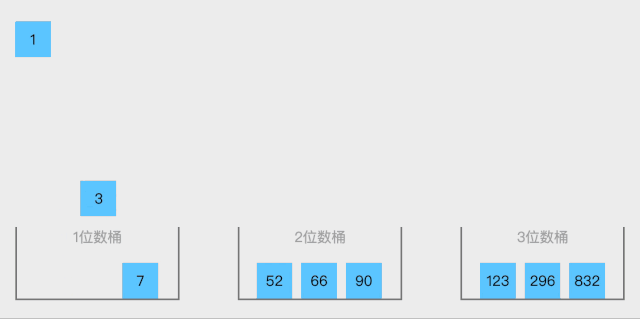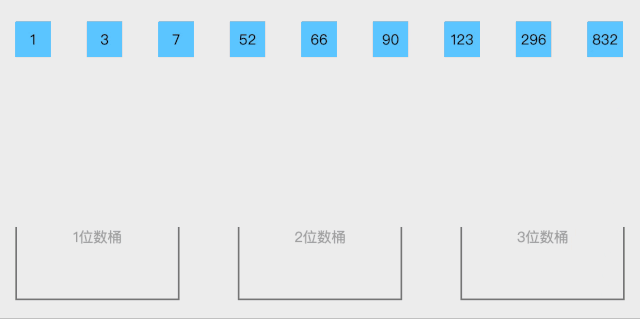
f9c64c9a4005888a34d6924613556902.gif
CodeBlock Loading...
基数排序
基数排序(Radix Sort)是一种非比较的整数排序算法,适用于对整数或特定长度的字符串进行排序。基数排序按位或按数字的位数进行排序,从最低有效位(LSD,Least Significant Digit)到最高有效位(MSD,Most Significant Digit)进行多轮排序,最终实现整个数组的有序排列。
基数排序的基本思想
基数排序的核心思想是将待排序的数字按位(从低到高或从高到低)进行排序。由于基数排序依赖于对每一位的排序,通常会借助于稳定的排序算法(如计数排序或桶排序)来保证在每一轮排序后,相同位数的元素保持其相对顺序。
基数排序的步骤
- 确定最大值的位数:找到数组中最大元素的位数,这将决定排序的轮数。
- 从最低位开始排序:从最低位开始,对每一位上的数字进行排序。排序时可以使用稳定的排序算法,比如计数排序。
- 重复:依次对更高的每一位进行排序,直到最高位。
- 最终排序结果:完成所有位的排序后,数组就是有序的。
示例
假设要对整数数组 [170, 45, 75, 90, 802, 24, 2, 66] 进行基数排序:
- 确定最大值的位数:最大值
802有 3 位,所以排序需要进行 3 轮。 第一轮(按个位排序):
- 排序结果:
[170, 90, 802, 2, 24, 45, 75, 66]
- 排序结果:
第二轮(按十位排序):
- 排序结果:
[802, 2, 24, 45, 66, 170, 75, 90]
- 排序结果:
第三轮(按百位排序):
- 排序结果:
[2, 24, 45, 66, 75, 90, 170, 802]
- 排序结果:

img
CodeBlock Loading...